Our experience on Day 0 of JPR11 yielded a nice example of the need to choose an appropriate implementation of an abstract concept. As I mentioned in the previous post, we experimented with Michael Barker’s Scala implementation of Guy Steele’s parallelizable word-splitting algorithm (slides 51-67). Here’s the core of the issue.
Given a type-compatible associative operator and sequence of values, we can fold the operator over the sequence to obtain a single accumulated value. For example, because addition of integers is associative, addition can be folded over the sequence:
1, 2, 3, 4, 5, 6, 7, 8
from the left:
((((((1 + 2) + 3) + 4) + 5) + 6) + 7) + 8
or the right:
1 + (2 + (3 + (4 + (5 + (6 + (7 + 8))))))
or from the middle outward, by recursive/parallel splitting:
((1 + 2) + (3 + 4)) + ((5 + 6) + (7 + 8))
A 2-D view shows even more clearly the opportunity to evaluate sub-expressions in parallel. Assuming that addition is a constant-time operation, the left fold:
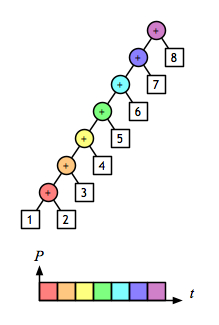
and the right fold:
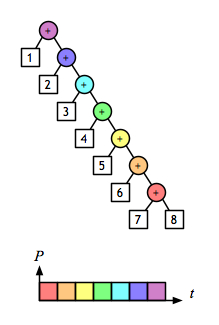
require linear time, but the balanced tree:
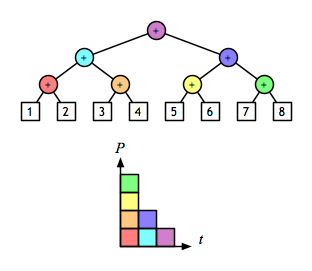
can be done in logarithmic time.
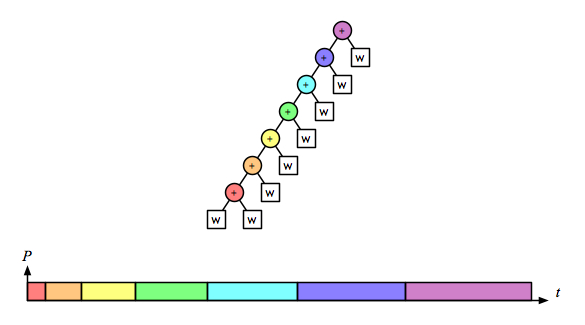
But the associative operation for the word-splitting task involves accumulating lists of words. With a naive implementation of linked lists, appending is not a constant-time operation; it is linear on the length of the left operand. So for this operation the right fold is linear on the size of the task:
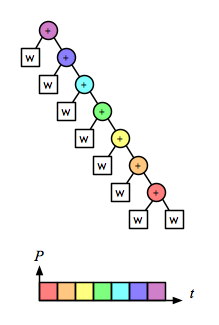
the left fold is quadratic:
and the recursive/parallel version is linear:
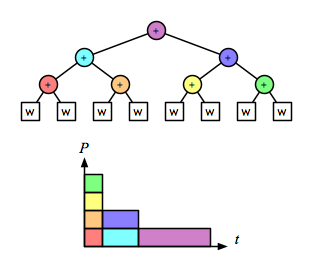
Comparing just the “parallel-activity-versus-time” parts of those diagrams makes it clear that right fold is as fast as the parallel version, and also does less total work:
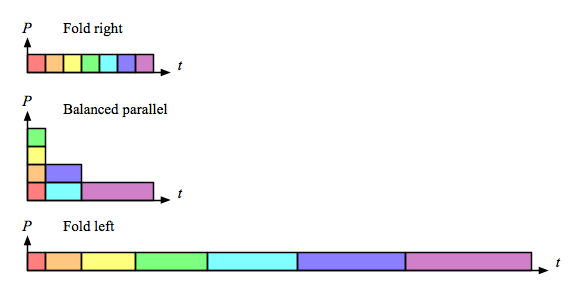
Of course, there are other ways to implement the sequence-of-words concept, and that is the whole point. This little example provides a nice illustration of how parallel execution of the wrong implementation is not a win.
The title of this post is a not-very-subtle (but respectful) reference to “Why Functional Programming Matters“, an excellent summary by John Hughes that deserves to be more widely read.
Purely Functional Data Structures, by Chris Okasaki, covers a nice collection of algorithms that avoid the trap mentioned above.

Also, video from this year’s Northeast Scala Symposium is now on-line for the session on functional data structures in Scala, presented by Daniel Spiewak.

Comments
I believe you meant “right” fold. Other than that, excellent post!
Yes, thanks for catching my typo. I’ve corrected it.
How many addition steps are done in the balanced tree approach vs unbalanced? It looks the same to me.
If you can do all of the additions on one row at the same time you’ll have logN steps.
In the case of e.g. addition, the total work is the same for all three (ignoring communication overhead). But for the list append operation in the last part of the post (using a naive implementation), there is extra work due to traversing the accumulating left-side elements more than once. The total number of “steps” is the same (if one append counts as one step), but the amount of each work done per step increases moving from the leaves to the root.
Great post, what did you use to make those graphs?
Thanks, Fred! The diagrams were made with OmniGraffle.
Hi @Joelneely,
Please forgive my ignorance, can you kindly explain why this is so? I.e. “right fold is linear on the size of the task … the left fold is quadratic:”?
Many thanks!
Ed
Hi, Edward,
The naive implementation of immutable lists will walk its left argument, creating a copy as it goes, ending with a reference to its right argument when the left copy bottoms out.
Looking at the tree, we can see that the right fold always has a left argument of length 1, so 1+1+…+1 is linear. But the left fold has progressively longer left arguments because the accumulation is happening on the left, giving 1+2+3+…+(n-1), which is quadratic.
Thanks @Joelneely!
When discussing the different ways to perform the sums of the integers, you claim that the balance tree approach is performed in log N time. This is not correct — count your number of additions. You still have to perform every addition. The only way it could be logarithmic in time is if you threw out half of the values in every steps — e.g., the way a binary search works. Obviously, with the addition, you don’t do that.
Actually, it is correct — count the number of levels in the diagram. The four additions at the bottom of the tree are all done in parallel, the two additions above those sums are done in parallel, and the final addition at the root is done last. All seven additions are still performed, but in only three units of time.
You’re mixing issues. N additions are still being made.
If you have enough processors relative to the size of your data set, then the execution time will come out logarithmic. If you don’t have enough processors, then it won’t time logarithmic time. Long story short, I feel that there are several assumptions in that analysis which you just brushed over without explaining.