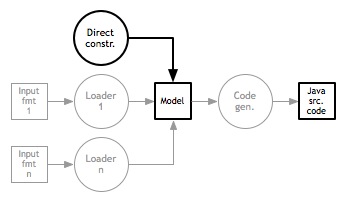
This post describes the first model in Haskell for the BuilderBuilder task. We will develop the model incrementally until we have rough parity with the Java version.
I’m experimenting with ways to distinguish user input from system output in transcripts of interactive sessions. This time I’m trying color, using a medium blue for output. I will appreciate feedback on whether that works for you.
Step one: defining and using a type
The simplest possible Haskell version of our model for a Java field is:
data JField = JField String String
However, the PMNOPML (“Pay Me Now Or Pay Me Later”) principle says that we’ll regret it if we stop there. In fact, later comes quickly.
We can create an instance of JField in a source file:
field1 = JField "name1" "Type1"
To do the same in a ghci session, prefix each definition with let, as in:
*Main> let field1 = JField "name1" "Type1"
Step two: showing the data
Trying to look at the instance yields a fairly opaque error message.
*Main> field1
<interactive>:1:0:
No instance for (Show JField)
arising from a use of `print' at <interactive>:1:0-5
Possible fix: add an instance declaration for (Show JField)
In a stmt of a 'do' expression: print it
Remember that in Java the default definition of toString() returns something like com.localhost.builderbuilder.JFieldDTO@53f67e; that’s also obscure at first glance. Haskell just goes a bit further, complaining that we haven’t defined how to show a JField instance. We can ask for a default implementation by adding deriving Show to a data type definition:
data JField = JField String String deriving Show
After loading that change, we get back a string that resembles the field’s defining expression:
*Main> field1
JField "name1" "Type1"
Step three: referential transparency
Our first model represented a Java class by its package, class name, and enclosed fields. The Haskell equivalent is:
data JClass = JClass String String [JField] deriving Show
The square brackets mean “list of …”, so a JClass takes two strings and a list of JField values. I’ll say more about lists in a moment, but first let’s deal with referential transparency.
We can build a class incrementally:
field1 = JField "name1" "Type1"
field2 = JField "name2" "Type2"
class1 = JClass "com.sample.foo" "TestClass" [field1, field2]
or all at once:
class1 = JClass "com.sample.foo"
"TestClass"
[ JField "name1" "Type1" ,
JField "name2" "Type2"
]
and get the same result:
*Main> class1
JClass "com.sample.foo" "TestClass" [JField "name1" "Type1",JField "name2" "Type2"]
As mentioned previously, only one of those definitions of class1 can go in our program. To Haskell, name = expression is a permanent commitment. From that point forward, we can use name and expression interchangeably, because they are expected to mean the same thing. That expectation would break if we were allowed to give name another meaning later (in the same scope).
Consequently, we can define a class using previously defined fields, or we can just write everything in one definition, nesting the literal fields inside the class definition. As we’ll see later, this also has implications for how we write functions; a “pure” function and its definition are also interchangeable.
Step four: lists
The array is the most fundamental multiple-valued data structure in Java; the list plays a corresponding role in Haskell. In fact, lists are so important that there are a few syntactical short-cuts for dealing with lists.
- Type notation: If
t is any Haskell type, then [t] represents a list of values of that type.
- Empty lists: Square brackets with no content, written as
[], indicate a list of length zero.
- Literal lists: Square brackets, enclosing a comma-separated sequence of values of the same type, represent a literal list.
- Constructing lists: The
: operator constructs a new list from its left argument (a single value) and right argument (a list of the same type).
For example, ["my","dog","has","fleas"] is a literal value that has type [String] and contains four strings. "my":["dog","has","fleas"] and "my":"dog":"has":"fleas":[] are equivalent expressions that compute the list instead of stating it as a literal value.
By representing the fields in a class with a list, we achieve two benefits:
- The number of fields can vary from class to class.
- The order of the fields is significant.
Step five: types and records
Given a JField, how do we get its name? Or its type? We can define functions:
fieldName (JField n _) = n
fieldType (JField _ t) = t
and do the same for the JClass data:
package (JClass p _ _ ) = p
className (JClass _ n _ ) = n
fields (JClass _ _ fs) = fs
but all that typing seems tiresome.
Before solving that problem, let’s note two other limitations of our current implementation:
- Definitions using multiple
String values leave us with the burden of remembering the meaning of each strings.
- The derived
show method leaves us with a similar problem; it doesn’t help distinguish values of the same type.
If you suspect that I’m going to pull another rabbit out of Haskell’s hat, you’re right. In fact, two rabbits.
Type declarations
We can make our code more readable by defining synonyms that help us remember why we’re using a particular type. By adding these definitions:
type Name = String
type JavaType = String
type Package = String
we can rewrite our data definitions to be more informative:
data JField = JField Name JavaType deriving Show
data JClass = JClass Package Name [JField] deriving Show
Record syntax
The second rabbit is a technique to get Haskell to do even more work for us. We represent each component of a data type as a name with an explicit type—all in curly braces, separated by commas:
data JField = JField {
fieldName :: Name ,
fieldType :: JavaType
} deriving Show
data JClass = JClass {
package :: Package ,
className :: Name ,
fields :: [JField]
} deriving Show
When we use this syntax, Haskell creates the accessor functions automagically, and enables a more explicit and flexible notation to create values. All of these definitions:
field1 = JField "name1" "Type1"
field1a = JField {fieldName = "name1", fieldType = "Type1"}
field1b = JField {fieldType = "Type1", fieldName = "name1"}
produce equivalent results:
*Main> field1
JField {fieldName = "name1", fieldType = "Type1"}
*Main> field1a
JField {fieldName = "name1", fieldType = "Type1"}
*Main> field1b
JField {fieldName = "name1", fieldType = "Type1"}
Step last: that’s it!
We have covered quite a bit of ground! The complete source code for the model appears at the end of this post. With both Java and Haskell behind us, we have most of the basic ideas we’ll need for the Erlang and Scala versions.
Recommended reading:
Real World Haskell , which is also available
, which is also available
for the Amazon Kindle
or on-line at the book’s web site. I really can’t say enough good things about this book.
The current BuilderBuilder mode in Haskell, along with sample data, is this:
-- BuilderBuilder.hs
-- data declarations
type Name = String
type JavaType = String
type Package = String
data JField = JField {
fieldName :: Name ,
fieldType :: JavaType
} deriving Show
data JClass = JClass {
package :: Package ,
className :: Name ,
fields :: [JField]
} deriving Show
-- sample data for demonstration and testing
field1 = JField "name1" "Type1"
field1a = JField {fieldName = "name1", fieldType = "Type1"}
field1b = JField {fieldType = "Type1", fieldName = "name1"}
field2 = JField "name2" "Type2"
class1 = JClass "com.sample.foo" "TestClass" [field1, field2]
studentDto = JClass {
package = "edu.bogusu.registration" ,
className = "StudentDTO" ,
fields = [
JField {
fieldName = "id" ,
fieldType = "String"
},
JField {
fieldName = "firstName" ,
fieldType = "String"
},
JField {
fieldName = "lastName" ,
fieldType = "String"
},
JField {
fieldName = "hoursEarned" ,
fieldType = "int"
},
JField {
fieldName = "gpa" ,
fieldType = "float"
}
]
}
Updated 2009-05-09 to correct formatting and add category.